
CELoss 식
: ground truth
: class i에 대한 score softmax값
: class 수
C에 2를 넣으면 BCE 식이 된다( Binary Cross Entropy )
segmentation에서 pixel-wisely 로 성능을 측정하는 보편적인 loss function으로, 이후의 distribution based loss들은 cross entropy의 변형이라고 볼 수 있음

BCELoss
또한 class가 두개이면 sigmoid=softmax가 되어
이진분류일때 sigmoid-BCE Loss와 softmax-CELoss는 같게됩니다
torch.nn.CrossEntropyLoss()
이 식과 torch.nn.CrossEntropyLoss의 동작은 조금 다르다
pytorch doc을 살펴보면
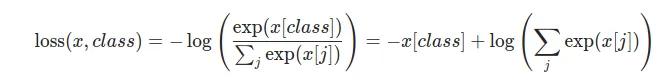
여기서 를 보면 익숙한 모양이 보인다.
softmax에 -log를 취한 모습. LogSoftmax이다.
따라서 softmax 레이어를 따로 추가하거나 함수처리 해 줄 필요가 없다.
또한 weight option으로 class별 가중치를 설정해줄 수 있다.
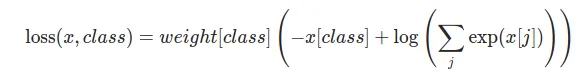
loss 는 각 minibatch마다 averaged된다.
•
loss로 들어가는 input : (N, C) Tensor
•
정답 input (y_batch) - (N, 1) Tensor
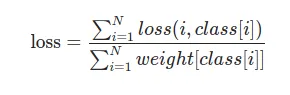
weight 설정을 안해준다면
가 될 것이다.
그 외 옵션
ignore_index (int, optional) | 무시되어 input gradient에 영향을 미치지 않을 target value 선택 |
reduction (string, optional) | reduction을 명시. ‘none’/’mean’/’sum’
’none’ : reduction 적용 x
’mean’: output의 weighted mean으로 처리됨
’sum’: output의 sum으로 처리됨
default : ‘mean’ |
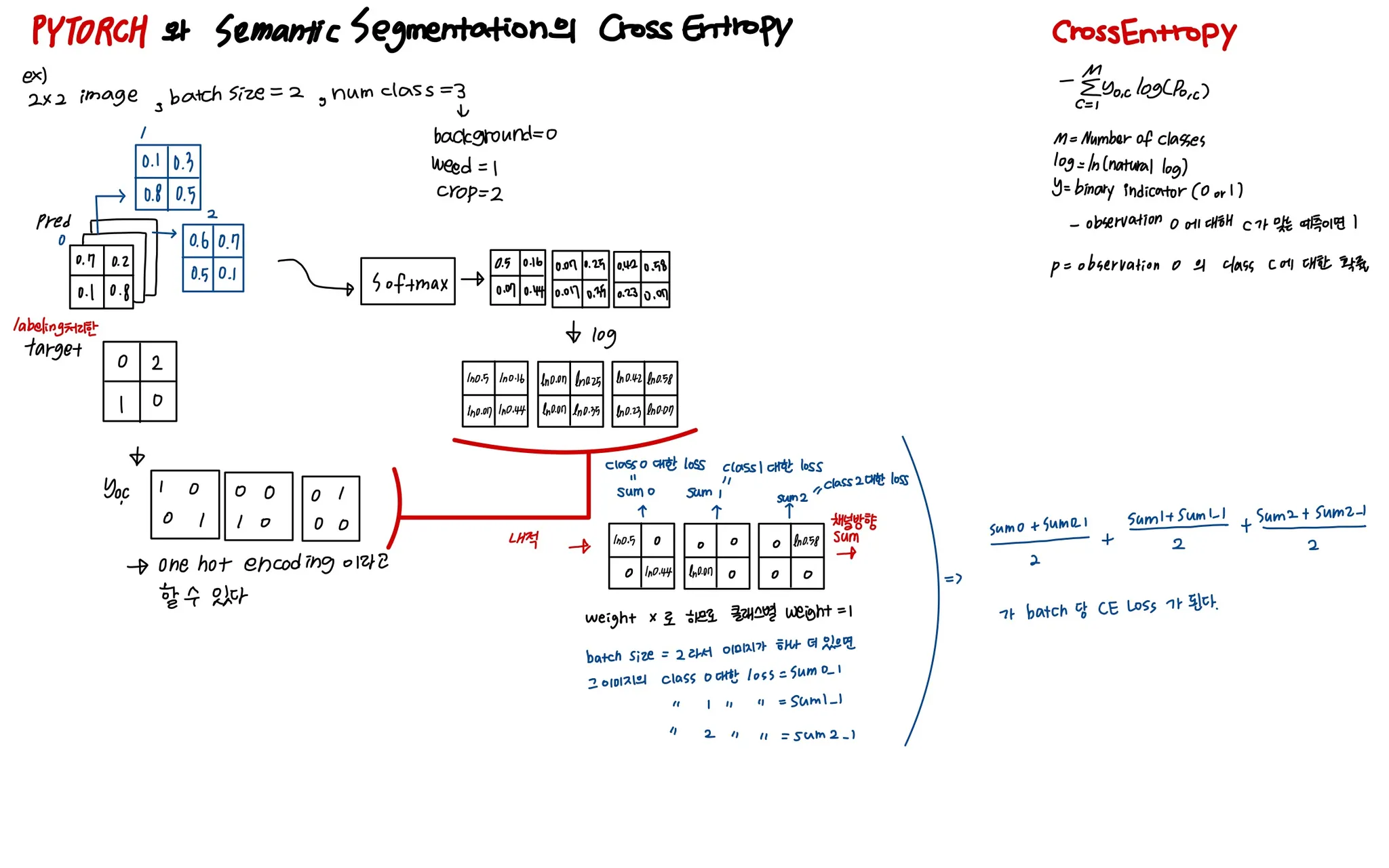
아 그리고 nn.CrossEntropyLoss()는 내부적으로 one-hot encoding도 수행해주므로 label map을 따로 one-hot encoding 해 줄 필요가 없다 ㅎㅎ
