ResNet모델에 대한 설명은 다음 페이지 참고
import torch
import torch.nn as nn
import sys
Python
복사
ResNet의 기본 블럭을 정의한 class Residual Block(nn.Module)
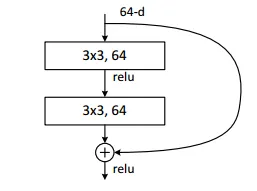
class ResidualBlock(nn.Module):
'''
F(x)+x
'''
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
# when the number of out channels is increased : in bottleneck architecture, use zeropadding, in basic block, use projection shortcut(F(x)+W_s * x)
ResidualBlock.expansion=1
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels*ResidualBlock.expansion, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels*ResidualBlock.expansion)
)
# the case that the number of input channels is not equal with the number of output channels
# in other cases, the result of self.shortcut is x
if stride != 1 or in_channels != out_channels * ResidualBlock.expansion:
self.shortcut=nn.Sequential(
nn.Conv2d(in_channels, out_channels*ResidualBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*ResidualBlock.expansion)
)
else:
self.shortcut = nn.Sequential()
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv_layers(x) + self.shortcut(x)
x = self.relu(x)
return x
Python
복사
nn.Module을 상속받은 형태로 구현했습니다.
일단 ResNet의 기본 블록은
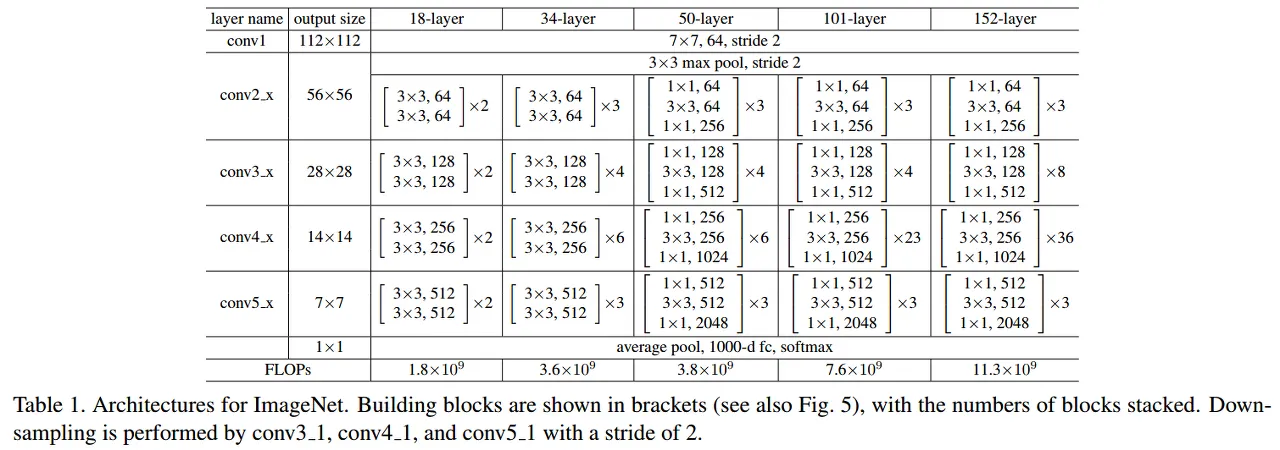
표에서 보이는 것처럼 레이어(이 표에서 정의한 conv1, conv2_x, conv3_x, ...) 내에서 채널 확장이 없으므로 Residual.expansion = 1 이라는 클래스변수를 선언해줍니다( 이는 마지막에 ResNet 클래스에서 주요하게 활용됩니다 )
그리고 표에 설명된 바와 같이 conv layer들을 nn.Sequential()로 선언해줍니다
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels*ResidualBlock.expansion, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels*ResidualBlock.expansion)
)
Python
복사
ResNet논문에 따르면,
입력차원 < 출력차원일 경우 Shortcut이 stride 2, kernel size 1로 projection shortcut이 적용된다고 하는데, (추가파라미터 필요) 이를 코드로 나타낸 것이
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut=nn.Sequential(
nn.Conv2d(in_channels, out_channels*BottleNeck.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*BottleNeck.expansion)
)
Python
복사
이것입니다.
입력차원<출력차원인 경우의 조건을 if stride != 1 or in_channels != out_channels * BottleNeck.expansion: 이렇게 지정했습니다. stride가 2이거나, input 채널수와 output 채널수가 다른경우로, 사실 이는 이 클래스에서는 필요하지 않습니다(논문과 똑같이 구현할 경우) 대신 BottleNeck 구현 클래스에서 표에 나온 것처럼 마지막 conv레이어의 출력 차원이 늘어나므로, 그 때 쓰이는 부분입니다. 그러나 기본 블럭 구현에도 넣어주었습니다.
입력차원과 출력차원이 같다면 shortcut은 그냥 x와 같게됩니다.
else: self.shortcut = nn.Sequential()
# inference
def forward(self, x):
x = self.conv_layers(x) + self.shortcut(x)
x = self.relu(x)
return x
Python
복사
그러면 이제 inference할 경우 conv 레이어와 shortcut을 더한 후 relu취한 값을 결과값으로 리턴해주게됩니다.
(오류경험) 여기서 self.relu를 따로 만들어주지않고 return nn.ReLU(x)할 경우
BottleNeck 구조를 구현한 class BottleNeck(nn.Module)
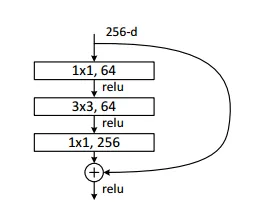
class BottleNeck(nn.Module):
'''
in 50, 101, 152-layer resnet
'''
def __init__(self, in_channels, out_channels, stride=1):
super(BottleNeck, self).__init__()
# when the number of out channels is increased : in bottleneck architecture, use zeropadding, in basic block, use projection shortcut(F(x)+W_s * x)
BottleNeck.expansion = 4 # Table 1: 128*4=512, 256*4=1024, 512*4=2048
self.conv_layers = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels*BottleNeck.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels*BottleNeck.expansion)
)
# the case that the number of input channels is not equal with the number of output channels
# in other cases, the result of self.shortcut is x
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut=nn.Sequential(
nn.Conv2d(in_channels, out_channels*BottleNeck.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*BottleNeck.expansion)
)
else:
self.shortcut = nn.Sequential()
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv_layers(x) + self.shortcut(x)
x = self.relu(x)
return x
Python
복사
여기선 table1의 내용과 같이, Bottleneck구조 마지막 conv레이어에서 차원확장이 이전레이어의 4배로 일어나므로 , BottleNeck.expansion = 4 로 클래스변수를 지정해줍니다.
그리고 nn.Sequential로 conv레이어들을 구현해줍니다 마찬가지로 conv- BN형태입니다
그 밑의 내용은 기본 블럭 구현(ResidualBlock class)와 같으므로 생략하겠습니다 
위의 두 블럭을 사용한 ResNet 구현 class Resnet(nn.Module):
이제 두 블럭으로 ResNet 을 구현해보겠습니다.
class Resnet(nn.Module):
'''
num_layers : the number of layers of ResNet ( i.e. 18, 34, 50, 101, 152 )
'''
def __init__(self, num_layers, num_classes=2, init_weights=True):
super(Resnet, self).__init__()
if num_layers == 18:
num_blocks = [2, 2, 2, 2]
block_class = ResidualBlock
elif num_layers == 34:
num_blocks = [3, 4, 6, 3]
block_class = ResidualBlock
elif num_layers == 50:
num_blocks = [3, 4, 6, 3]
block_class = BottleNeck
elif num_layers == 101:
num_blocks = [3, 4, 23, 3]
block_class = BottleNeck
elif num_layers == 152:
num_blocks = [3, 8, 36, 3]
block_class = BottleNeck
else:
print(" It's not appropriate number of layers ")
sys.exit(0)
self.in_channels = 64
self.conv1_n_maxpool = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv2_x = self._make_layers(block_class, num_blocks[0], 1, 64) # N, 64, 56, 56
self.conv3_x = self._make_layers(block_class, num_blocks[1], 2, 128) # N, 128, 28, 28
self.conv4_x = self._make_layers(block_class, num_blocks[2], 2, 256)
self.conv5_x = self._make_layers(block_class, num_blocks[3], 2, 512)
self.average_pool = nn.AdaptiveAvgPool2d((1,1)) # N, C, 1, 1
self.fc_layer = nn.Linear(512*block_class.expansion, num_classes)
def _make_layers(self, block_class, num_blocks, stride, out_channels):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers = layers + [block_class(self.in_channels, out_channels, stride)]
self.in_channels = out_channels * block_class.expansion
return nn.Sequential(*layers)
def forward(self, x):
output = self.conv1_n_maxpool(x)
output = self.conv2_x(output)
output = self.conv3_x(output)
output = self.conv4_x(output)
output = self.conv5_x(output)
output = self.average_pool(output)
output = output.view(output.size(0), -1)
output = self.fc_layer(output)
return output
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') # He initialization
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) # Fills the given 2-dimensional matrix with values drawn from a normal distribution parameterized by mean and std.
nn.init.constant_(m.bias, 0)
Python
복사
표를 기반으로 레이어 이름들도 동일하게 하려 했습니다.
중요한 부분인 def _make_layers(self, block_class, num_blocks, stride, out_channels): 부터 살펴보겠습니다.
def _make_layers(self, block_class, num_blocks, stride, out_channels):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers = layers + [block_class(self.in_channels, out_channels, stride)]
self.in_channels = out_channels * block_class.expansion
return nn.Sequential(*layers)
Python
복사
_make_layers < parameters >
•
block_class: resnet 모델에 따른(resnet 18, 34, 50, 101, 152) 사용 블록 종류 클래스(class ResidualBlock 또는 class Bottleneck) 가 들어갑니다.
•
num_blocks : 표에 있는 레이어별 블록의 개수가 resnet모델에 따라 다르게 리스트형태로 들어갑니다
if num_layers == 18:
num_blocks = [2, 2, 2, 2]
block_class = ResidualBlock
elif num_layers == 34:
num_blocks = [3, 4, 6, 3]
block_class = ResidualBlock
elif num_layers == 50:
num_blocks = [3, 4, 6, 3]
block_class = BottleNeck
elif num_layers == 101:
num_blocks = [3, 4, 23, 3]
block_class = BottleNeck
elif num_layers == 152:
num_blocks = [3, 8, 36, 3]
block_class = BottleNeck
else:
print(" It's not appropriate number of layers ")
sys.exit(0)
Python
복사
•
stride : table1을 보면 , conv1 → conv2_x넘어갈때를 제외하고 conv2_x→ conv3_x→ ... 이렇게 넘어가면서 차원 증가가 발생합니다. 따라서 conv2_x를 제외한 conv3_x, conv4_x, conv5_x 를 만들 때 2가 들어가게됩니다.
self.conv1_n_maxpool = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv2_x = self._make_layers(block_class, num_blocks[0], 1, 64) # N, 64, 56, 56
self.conv3_x = self._make_layers(block_class, num_blocks[1], 2, 128) # N, 128, 28, 28
self.conv4_x = self._make_layers(block_class, num_blocks[2], 2, 256)
self.conv5_x = self._make_layers(block_class, num_blocks[3], 2, 512)
self.average_pool = nn.AdaptiveAvgPool2d((1,1)) # N, C, 1, 1
self.fc_layer = nn.Linear(512*block_class.expansion, num_classes)
Python
복사
strides = [stride] + [1] * (num_blocks - 1)
이 부분의 경우 예를들어 resnet50의 conv3_x를 보면 bottleneck1 - bottleneck2 - bottleneck3 - bottleneck4 구조가 된다.
이 때 차원수 변화는 (input 256) → 128 → 128 → 512 (bottleneck1끝) → 128 → 128 → 512(Bottleneck2 끝) → 128 → 128 → 512(bottleneck 3끝) →128 → 128 → 512(bottleneck 4 끝)
conv2_x → conv3_x로 넘어가는 bottleneck1에서만 stride 를 2로 하면 되므로 처음 이후의 stride는 1로 Bottleneck 클래스에 들어가도록 [stride, 1, 1, 1, ... ] 형태로 지정해주는 부분입니다.
그러면 이제 weigjt 초기화 함수를 보겠습니다.
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') # He initialization
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01) # Fills the given 2-dimensional matrix with values drawn from a normal distribution parameterized by mean and std.
nn.init.constant_(m.bias, 0)
Python
복사
self.module() 로 모듈들을 다 불러올 수 있습니다. for문 돌려서
Conv2d레이어들은 He initialization되고
BatchNorm2d레이어들은 weight는 1로, bias는 0으로 초기화됩니다
nn.Linear ( FC 레이어들)은 weight들은 mean이 0이고 std는 0.01인 정규분포를 따라 초기화되고, bias들은 0으로 초기화됩니다.
inference하는 부분인 forward함수
def forward(self, x):
output = self.conv1_n_maxpool(x)
output = self.conv2_x(output)
output = self.conv3_x(output)
output = self.conv4_x(output)
output = self.conv5_x(output)
output = self.average_pool(output)
output = output.view(output.size(0), -1)
output = self.fc_layer(output)
return output
Python
복사
논문과 같이 모든 레이어를 통과한 결과를 average pooling하고 1차원으로 펼쳐서 fc레이어를 통과해줍니다.
softmax부분은 train코드에서 다뤘습니다.
